ppap 서비스에서 RAG 챗봇을 어떻게 구축했는지 발표해달라는 요청이 와서 급하게 발표자료를 만들고 발표했다.
https://youtu.be/YKkzNylP65w?si=iWwrNF-u7BTk0JmR
작년에 했던 논문 발표와 크게 달라진 부분은 없다. 발표자료만 새로 만들었다.

작년 6월에 나온 평가지표를 기반으로 적정성 19개 항목 중 정량적인 부분을 기반으로 평가 자동화를 시도했다.
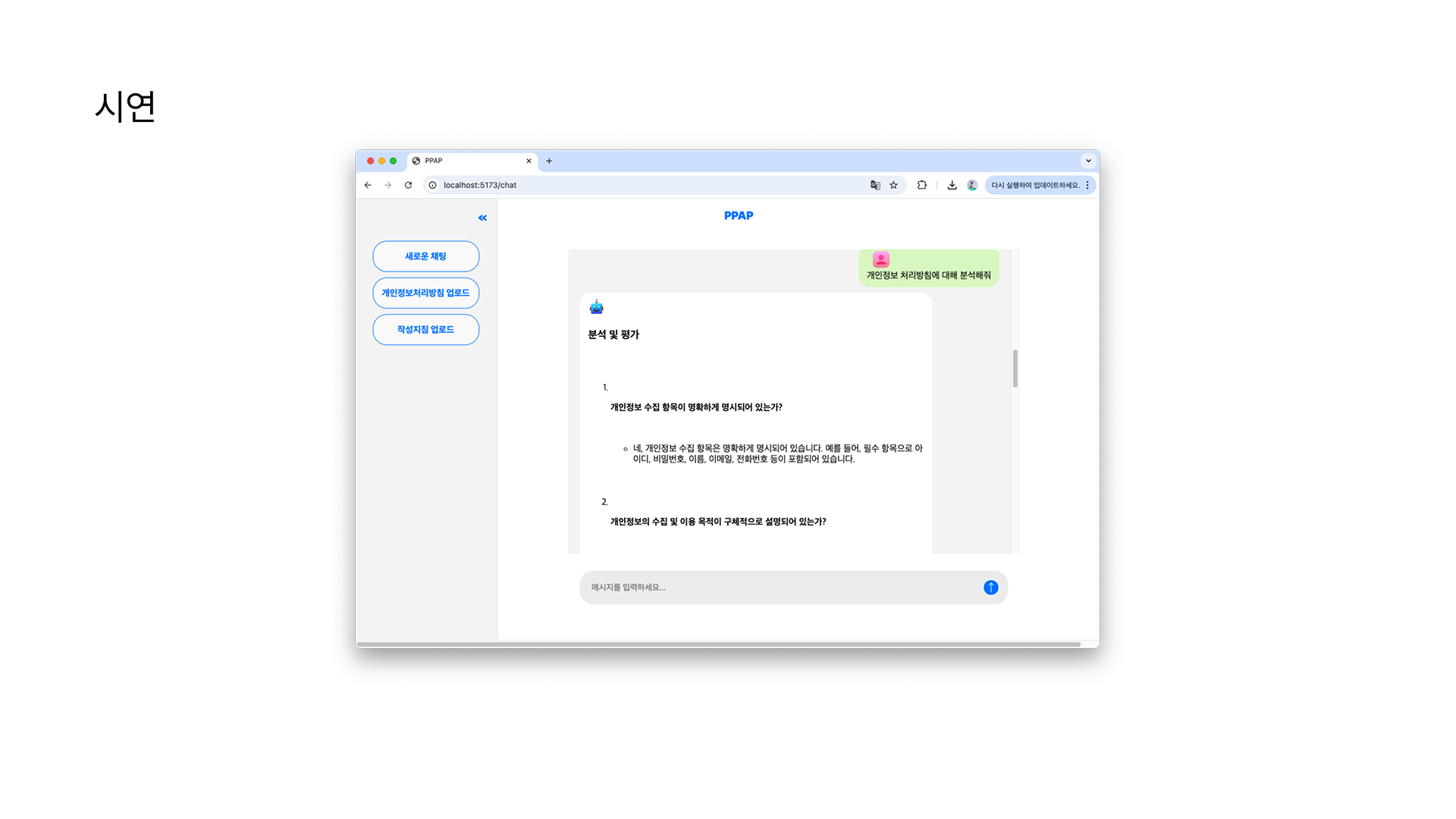
원한 건 ai한테 문서를 제공하면 ai가 사람이 하듯이 개인정보처리방침을 평가해서 그 결과를 제공하는 형태였다.
처음 멘토님이 제시한 프로젝트의 개요는 단순히 파이썬을 활용한다는 것 뿐이어서, ai 모델을 만들어야 할 것 같다는 생각을 했다. 근데 인공지능 개발 경험이 없는 상태였어서 기존 연구 논문만 계속 읽으며 지금 우리의 상황과 최대한 비슷한 케이스를 찾고자 했다.
크롤링 해온 텍스트 데이터에 개인정보처리방침 작성 가이드라인이나 법령에서 요구하는 필수 항목들이 제대로 명시되어있는지를 확인해야 했다.
이걸 고민할 때가 4~5월 쯤이었는데, 구체적인 평가 방식과 지표가 나오지 않은 상태여서 더욱더 데이터셋 구축 방식에 고민이 많았다. 다른 사람들 보면 파인튜닝을 한다는데, 거기에 필요한 코퍼스는 어디서 가져와야 하는지가 문제였다. 애초에 어떻게 유사도 검색을 구현하는지도 모르는 상태..
그러던 중 GPT 활용 개인정보처리방침 안전성 검증 기법이라는 논문이 눈에 들어왔다.
내가 모델을 직접 구현하긴 너무 어려우니까
GPT한테 일을 시키자!
GPT는 사람이 생각하고 말하는 것처럼 잘도 답변을 내놓는다. 그러나 3.5까지는 2021년 데이터까지만 학습해서 할루시네이션이 발생하는 문제가 있었다. 근데 마침 내가 작년에 SAP 인턴십을 준비하면서 Vector DB를 알게되고, RAG도 알게됐다. 이건 하늘이 RAG를 사용하라고 주신 기회같았다.
파인튜닝
파인튜닝 방식은 Pretrained LLM에 추가적인 파라미터를 넣고 미세조정하는 방식이다. 직접 처음부터 LLM을 만드는 대신 기존 LLM에 필요한 데이터만 갖다 붙이는 방식이라 간단해보이는데, 작년에 감정분석 ai 개발하던 친구들의 모습을 떠올려보면 결코 쉽지 않았다. 실제로도 고비용에 오랜 시간이 걸리고 PC의 성능 요구도 높았다.
프롬프트 엔지니어링
프롬프트 엔지니어링은 질문 시 답변 예시를 모델에게 제공해서 그와 유사한 답변을 생성할 수 있도록 유도하는 방법이다. 근데 원하는 말투같은걸 만들어낼 수는 있을 것 같은데, 이건 약간 템플릿 지정에 가깝고 법령 데이터를 제대로 모델에게 다 전달하기는 매우 어렵다고 생각했다.
기본적인 RAG는 문서 로드 - 문서 분할 - 문서 임베딩 - 벡터 검색 - 답변 생성 단계로 이루어진다.
/chat 쪽으로 요청을 보내면 FastAPI로 띄운 챗봇 응답을 보내주는 형태. 데이터는 FAISS에 저장하고, llm api는 OpenAI의 GPT-4o 모델을 호출한다.
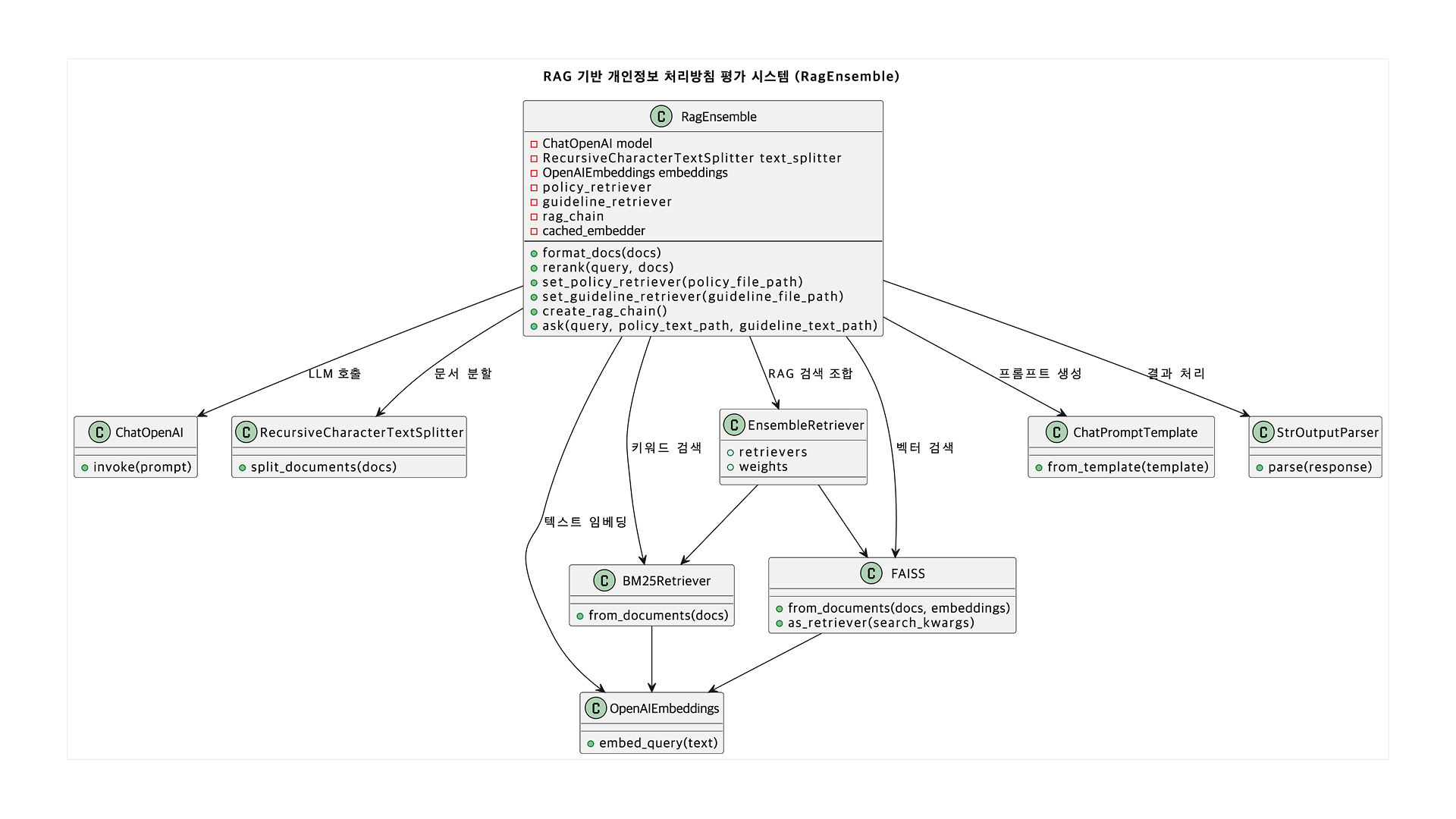
- Rerank : 유사도가 높은 순으로 검색 결과 문서 순위 재정렬
- EnsembleRetriever : FAISS Vectorstore Retriever + BM25 Retriever
- policy_retriever : 개인정보처리방침 검색기
- guideline_retriever : 처리방침 작성 가이드라인 검색기
'PPAP' 카테고리의 다른 글
| PPAP 개발기 (2) : API spec 문서 작성하기 (0) | 2024.10.02 |
|---|---|
| PPAP 개발기(1) (1) | 2024.10.01 |